딥러닝 Sequential 회귀분석 예측예제 (feat. 보스턴 집값예측)
카테고리: machine
딥러닝 활용
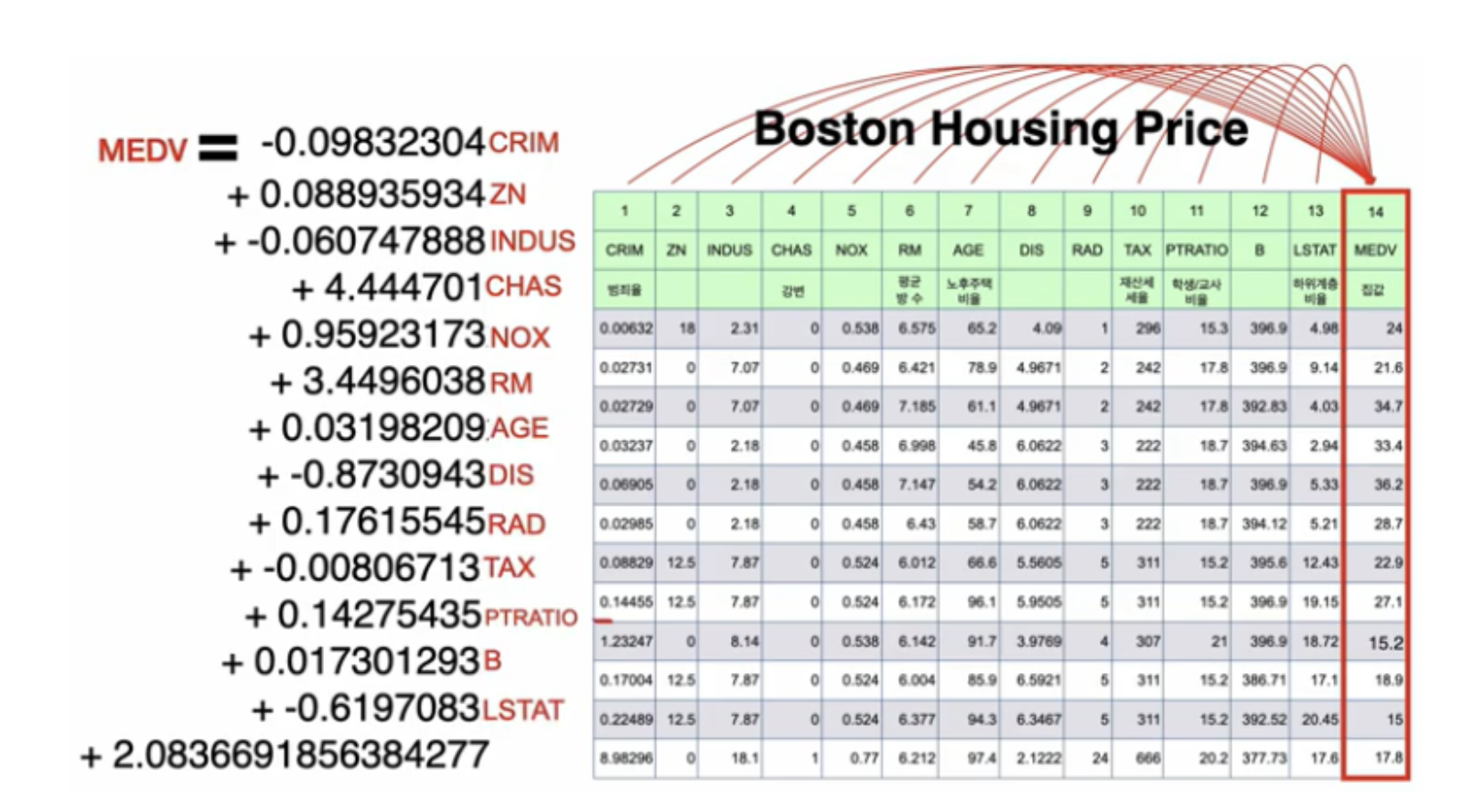
보스턴 집값 예측
데이터 불러오기: load_boston() 함수를 사용하여 보스턴 집값 데이터셋을 불러옵니다. 이 데이터셋은 보스턴 지역의 주택 가격과 관련된 여러 특성들을 포함하고 있습니다.
데이터 전처리: 입력 데이터인 X에는 주택 가격 예측에 사용될 여러 특성들이 들어있습니다. 이러한 데이터를 학습에 적합한 형태로 만들기 위해 StandardScaler를 사용하여 특성들을 평균 0, 표준편차 1인 표준화된 형태로 변환합니다. 이렇게 함으로써 각 특성의 값이 서로 다른 범위에 있을 때 발생할 수 있는 문제를 방지합니다.
훈련 데이터와 검증 데이터 분리: 전체 데이터를 훈련 데이터와 검증 데이터로 나눕니다. train_test_split 함수를 사용하여 훈련 데이터와 검증 데이터를 8:2 비율로 분리하고, 랜덤 시드를 고정하여 재현성을 확보합니다.
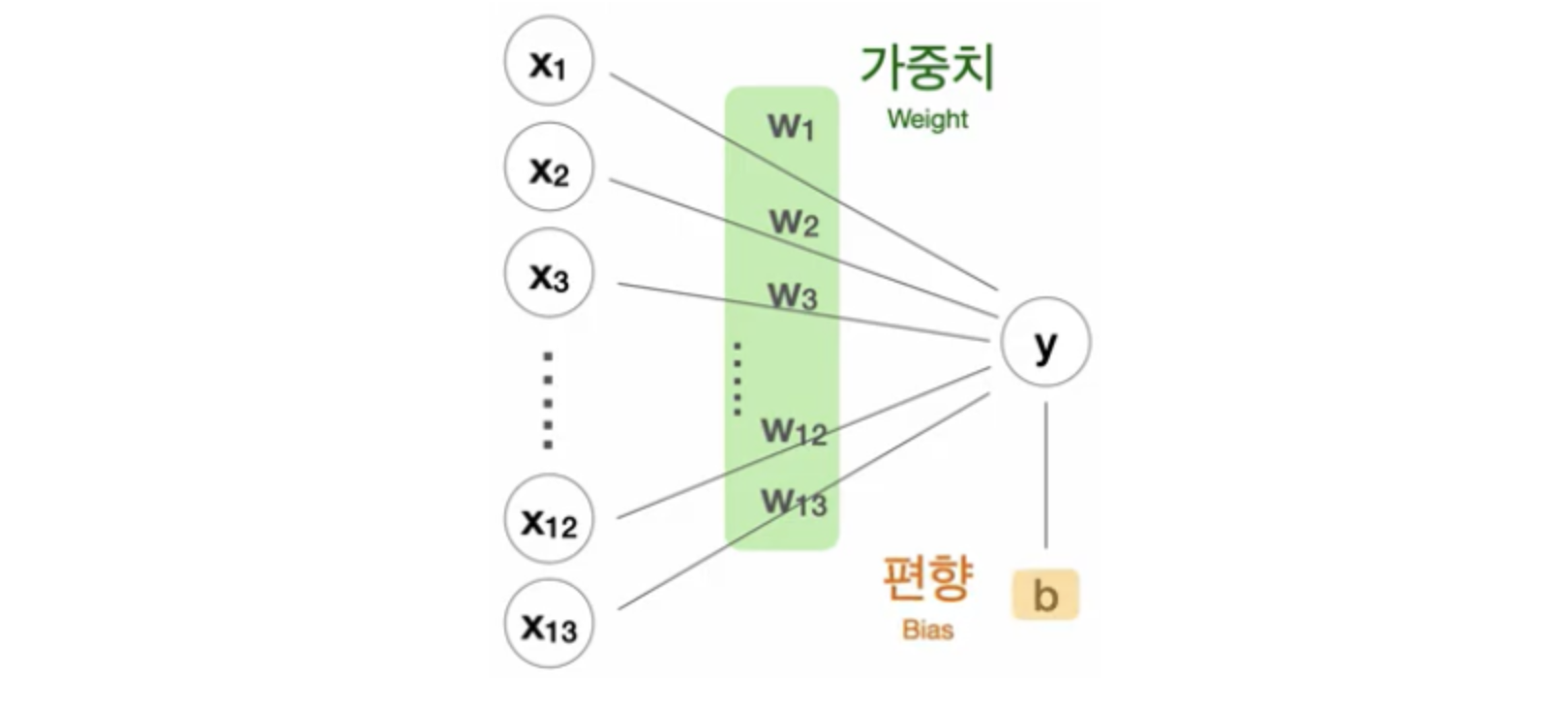
딥러닝 모델 구성: Sequential 클래스를 사용하여 딥러닝 모델을 구성합니다. 여기서는 Dense 층을 사용하여 완전 연결 신경망을 구성하였습니다. 각 은닉층마다 64, 128, 256의 뉴런 수를 가지고 있으며, 활성화 함수로는 ReLU를 사용하였습니다. 또한, 과적합을 방지하기 위해 각 은닉층 다음에 Dropout 층을 추가하여 일부 뉴런을 무작위로 꺼줍니다. 마지막으로 출력 층은 하나의 뉴런을 가지고 있으며, 활성화 함수를 사용하지 않습니다. 이 모델은 회귀 문제이므로 예측값을 직접 계산하기 때문에 활성화 함수가 필요하지 않습니다.
모델 컴파일: 손실 함수로는 평균 제곱 오차(mean squared error, MSE)를 사용하고, 최적화 알고리즘으로는 Adam을 선택하여 모델을 컴파일합니다. 이렇게 함으로써 모델이 예측한 값과 실제 타깃 값과의 차이를 최소화하는 방향으로 모델이 학습될 수 있습니다.
조기 종료 및 모델 저장 설정: EarlyStopping 콜백을 사용하여 검증 손실이 더 이상 감소하지 않으면 학습을 조기에 종료하도록 설정하고, ModelCheckpoint 콜백을 사용하여 검증 손실이 최소값일 때 모델을 저장하도록 설정합니다. 이를 통해 최적의 모델을 자동으로 저장할 수 있습니다.
모델 학습: fit 메서드를 사용하여 모델을 학습시킵니다. 훈련 데이터와 검증 데이터를 사용하며, 에포크(epoch)를 100으로 설정하여 모델을 최대 100번까지 학습시킵니다. callbacks 매개변수에 앞서 설정한 EarlyStopping과 ModelCheckpoint 콜백을 넣어주어 조기 종료 및 모델 저장을 수행합니다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 보스턴 집값 예측
boston = load_boston()
X = boston.data
y = boston.target
# Standard Scaler Data Preprocessing
scaler = StandardScaler()
X = scaler.fit_transform(X)
# Train test Split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
# 딥러닝 모델
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(X_train.shape[1],))) # 첫 번째 히든 레이어
model.add(Dropout(0.2)) # Dropout 적용
model.add(Dense(64, activation='relu')) # 두 번째 히든 레이어
model.add(Dropout(0.2)) # Dropout 적용
model.add(Dense(128, activation='relu')) # 세 번째 히든 레이어
model.add(Dropout(0.2)) # Dropout 적용
model.add(Dense(256, activation='relu')) # 네 번째 히든 레이어
model.add(Dropout(0.2)) # Dropout 적용
model.add(Dense(128, activation='relu')) # 다섯 번째 히든 레이어
model.add(Dropout(0.2)) # Dropout 적용
model.add(Dense(1)) # 출력 레이어
# loss funtion, optimizer
model.compile(loss='mean_squared_error', optimizer='adam')
# Early stopping
estopping = EarlyStopping(monitor='val_loss', patience=5)
# ModelCheckpoint
mcheckpoint = ModelCheckpoint('model_best.h5', monitor='val_loss', save_best_only=True)
# model train
history = model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=100, callbacks=[estopping, mcheckpoint])
예측하기
import tensorflow as tf
from tensorflow.keras.models import load_model
from sklearn.preprocessing import StandardScaler
# 저장한 모델 불러오기
model = load_model('model_best.h5')
# 새로운 입력 데이터 준비 (예제 데이터, 필요에 따라 실제 데이터로 대체해야 합니다.)
new_data = [[0.00632, 18.0, 2.31, 0.0, 0.538, 6.575, 65.2, 4.0900, 1.0, 296.0, 15.3, 396.90, 4.98]]
# 입력 데이터도 이전과 동일하게 StandardScaler로 스케일링해야 합니다.
scaler = StandardScaler()
new_data_scaled = scaler.fit_transform(new_data)
# 예측하기
predicted_prices = model.predict(new_data_scaled)
# 예측 결과 출력
print("예측된 집값:", predicted_prices[0][0])
댓글남기기